
Harnessing the best of both Data Fabric and Data Mesh architectures

Hi, I'm Paul and I write blogs to help process the thoughts in my head... :-)
AKA, the musings (post series link) of a slightly grumpy, battle hardened data engineer, technology strategist and enterprise architect.
Context
In the constantly evolving landscape of data platform tooling, businesses are increasingly seeking robust and innovative solutions to rapidly onboard the vast amounts of data generated by source systems. AKA the big data problem as it was once known, still relative, still the same issues. I’ve therefore been wondering if we could integrate both Data Fabric and Data Mesh architectures to offer a potential (in most cases, unproven) approach to developing a comprehensive cloud-native data solution that delivers both operational and analytical requirements.
By leveraging the strengths of both architectures, could businesses achieve seamless data integration, improved governance, simplified operating models, rapid data delivery, scaled data product delivery and enhanced analytical capabilities. A rhetorical question for now and maybe an impossible task with current tools. Hence the blog post, so we can explore this and help try to reach a conclusion with the support of our excellent community.
I think its also fair to say, I’m not the first to have these thoughts. Considering the recent announcements from Microsoft Ignite with regards to SQL databases now available as part of Microsoft Fabric, it would seem the big software vendors are already leaning into this idea. But lets not get ahead of ourselves with technical solutions, yet!
Further Background
Next, a little more background on the respective architecture, and to give credit where credit is due. Those previously leading the evolution/disruption of data platform thinking in our industry. A very short summary of the fabric and the mesh:
Data Fabric
The concept of a Data Fabric architecture was initially coined by Gartner. Data Fabric is a design concept that provides a unified and intelligent platform for managing data across multiple environments. It facilitates seamless data access and sharing, enabling businesses to derive insights from their data regardless of its location. Data Fabric emphasizes metadata-driven management, data governance, and automation, ensuring that data remains consistent, secure and accessible. Importantly, for both operational and analytical purposes.
This all sounds great, but very aspirational and playing to ideals rather than technology. No surprise considering it came from Gartner. Moving on.
Data Mesh
The principles of a Data Mesh architecture were pioneered by Zhamak Dehghani, a leading figure in data management having published other books on the topic. As a consultant at Thought Works (at the time), Zhamak introduced the Data Mesh to address the limitations of traditional centralised data architectures. This approach advocates for a decentralised, domain-driven model, moving away from monolithic systems. By treating data as a product and assigning each domain owner the responsibility of delivering its respective insights. Data Mesh fosters a more agile and scalable data ecosystem, considering the common three parts to the problem of technology, people and processes in its implementation.
Like fabric, sounds great, but very ambition and lacking a lot of real world technical solutions to the principles defined.
Operational and Analytical Integration
To continue the thinking and focus of this blog, we need to double down on that primary goal. The idea of combining these architectures to integrate online transactional processing (OLTP) datasets with online/offline analytical processing (OLAP) functions at both the data product level. This integration would ensure businesses can derive insights from their operational data in near real-time, enabling informed decision-making and improved operational efficiency.
If considering a combined Data Fabric and Data Mesh architecture, OLTP data could be processed and stored in the same cloud-native data platform. This data could then be made available for analytical processing through well-defined data products and business domains. By leveraging the metadata-driven management and automation capabilities of Data Fabric, along with the domain-centric principles of Data Mesh, businesses could achieve seamless data integration and governance. Minus the traditional pipeline ingestion efforts and time to deliver datasets.
Combining Fabric and Mesh
The combination of Data Fabric and Data Mesh architectures could offer a comprehensive solution that addresses these complexities in modern data platform solutions. This level of cooperation could leverage the strengths of both architectures to create a cloud-native, decentralised data platform that is both robust and flexible. With shared ownership to drive innovation and time to insights.
That said, and holding myself to the same criticisms of the other thought leaders, is it really possible?
Today, I think the main pain point in creating such a platform is the operational and analytical data integration, as described above. If the business controls all elements of the solution build, this could work. That is a big ‘if’ though. In the spirit of scaling and rapid growth many businesses will (of course) buy SaaS hosted tooling to support operations. And why not, we can’t grow a business, especially a digital native business by building every scrap of software ourselves just so we later have seamless analytics. Ultimately, this means potential integration friction and more pipelines to copy/extract data from third party sources before analytical workloads can take place.
A long time ago in a galaxy far far away I attempted a strawman architecture picture of this idea. Shown below. Not perfect and it never really stuck and became another high bar to entry. But the premise has continued to fester. Hence the blog.
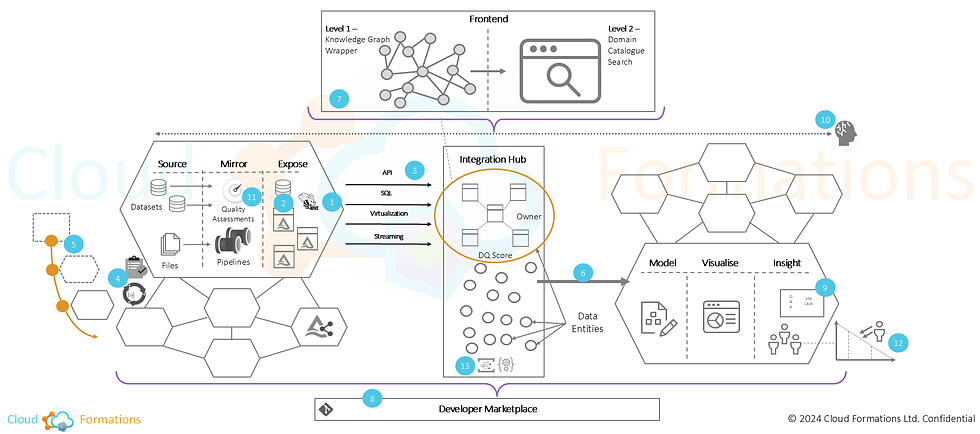
|
Maybe the better question we need to ask: will data ingestion ever become a thing of the past? In 2024, the only hope we might have is the support of a well-trained AI model to accelerate that can understand/interpret data sources structures. Like our CF.Nimbus product does for most ANSI SQL databases. It this context though, I mean well-trained to the point of making the connection and ingest activities seamless. No human input required beyond the initial configuration. Like the automatic hand-sake we get when connecting hardware via USB-C ports. A degree of awareness on both sides, connections and appropriate services established. For example, power and/or data exchange.
We might even go as far as considering this a standard plane of metadata interoperability that could be used to reduce that integration friction. But, that can be a musing blog for another time.
Initial Conclusions
To conclude this blog for now, because its getting too long, in the Microsoft ecosystem where I’ve spent my career I’ve seen a few possible attempts at this level of integration. Focusing on the ingest part of the wider architecture initially:
Column store indexes for SQL Server database tables. Giving us columnar compression to assist analytical outputs from operational tables. Far from perfect and lacking in the data modelling required. But not a bad idea, at the time.
Using the transaction change feed from Azure Cosmos Databases to push records into analytical data stores for analytical workloads. Certainly not seamless, but near real-time in terms of change data capture (CDC) and scalable with Azure Functions Apps.
Exploring Microsoft’s Database Mirroring and now Open Mirroring capabilities for some data source in Microsoft Fabric. Still immature as a product feature, but it has potential to reduce the ingestion friction if the data source is semi controlled by the business.
The level of architecture folding (as I’m going to call it) between Data Fabric and Data Mesh still needs a lot more thinking and design. But for now I wanted to at least scratch the surface of where I’m planning to do some spikes of research to tease out these ideas.
To be continued.
Many thanks for reading.

Comments